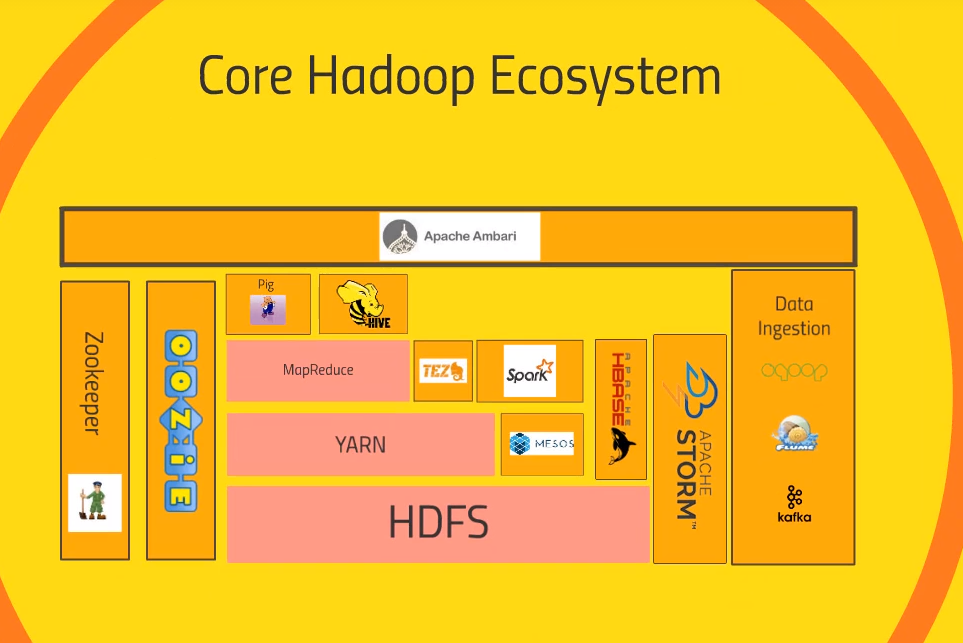
Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.

- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
- Hadoop Ozone: An object store for Hadoop
- Ambari™: A web-based tool for provisioning, managing, and monitoring Apache Hadoop clusters which includes support for Hadoop HDFS, Hadoop MapReduce, Hive, HCatalog, HBase, ZooKeeper, Oozie, Pig and Sqoop. Ambari also provides a dashboard for viewing cluster health such as heatmaps and ability to view MapReduce, Pig and Hive applications visually alongwith features to diagnose their performance characteristics in a user-friendly manner.
- Avro™: A data serialization system.
- Cassandra™: A scalable multi-master database with no single points of failure.
- Chukwa™: A data collection system for managing large distributed systems.
- HBase™: A scalable, distributed database that supports structured data storage for large tables.
- Hive™: A data warehouse infrastructure that provides data summarization and ad hoc querying.
- Mahout™: A Scalable machine learning and data mining library.
- Pig™: A high-level data-flow language and execution framework for parallel computation.
- Spark™: A fast and general compute engine for Hadoop data. Spark provides a simple and expressive programming model that supports a wide range of applications, including ETL, machine learning, stream processing, and graph computation.
- Submarine: A unified AI platform which allows engineers and data scientists to run Machine Learning and Deep Learning workload in distributed clusters.
- Tez™: A generalized data-flow programming framework, built on Hadoop YARN, which provides a powerful and flexible engine to execute an arbitrary DAG of tasks to process data for both batch and interactive use-cases. Tez is being adopted by Hive™, Pig™ and other frameworks in the Hadoop ecosystem, and also by other commercial software (e.g. ETL tools), to replace Hadoop™ MapReduce as the underlying execution engine.
- ZooKeeper™: A high-performance coordination service for distributed applications.


HDFS
- Breaks files into blocks
- Stores across several commodity computers and each block is replicated more than once to ensure data reliability in case one node goes down.
Name Node – is like an index to the files(blocks) stored and data nodes. (Namenode )
Data Node – it actually stores the data
Client node asks for a file to Name Node and then goes to get it from the data nodes.
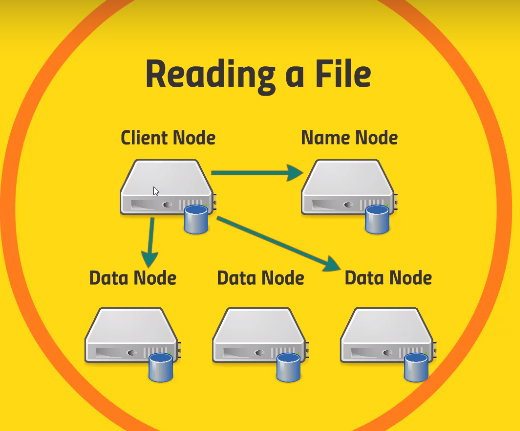
Writing – Client node hands over to Name node and it hands over it the name of data node. The client talks to Data node which inturn talk to other data nodes to get the file saved across them along with replication. They all respond back to the Client node and to Name Node .

NameNode Resilience


MapReduce

- Mapper – maps to key value pairs
- Shuffle and sort – groups and sorts the key value pairs
- Reducer – Reduces the input to a single value
Below is example to find the no. of movies rated by each user

What’s happening in the system. Client node talks to YARN which talks to NodeManager which in turn talks to Node and they output it on HDFS. If Node goes down then NodeManager shifts/restarts process on another Node, if NodeManager goes down, its handled by YARN, if YARN goes down then High availability (HA) replica of it takes over (as discussed previously).

An example where we want to display Movie id and count of ratings for the movie. (Sort movies according its rating)

The need for a second reducer is that we needed sorted output (as per the count of ratings). The map step only maps but the framework does the “sort and shuffle” on it according to the key. Note – framework takes everything as string so we need to zero pad the numbers for proper sorting.
The key being movieId in mapper would sort according to it. So, we change the order of key and value in the reducer. This ensures that <count,movieId> sorts in the order of count.
1 , abc(assume string as movieid)
2, bef, gef
100, ded
Now to display it in sorted order according to no of ratings, another reducer which reverses the key and value, and in this sort is introduced by sorting algo and not by framework.
Abc, 1
Bef , 2
Gef, 2
Ded, 100
Pig
Pig is a data flow language and execution engine. Pig has a scripting language pig-latin in which you can write map reduce steps/functions. They give a good performance too and it’s easier to write it than map-reduce using Python/Java.

Built on top of MapReduce and Tez. Use Pig by 1. Grunt 2.Ambari/Hue 3. Script
Example of getting top rated movies
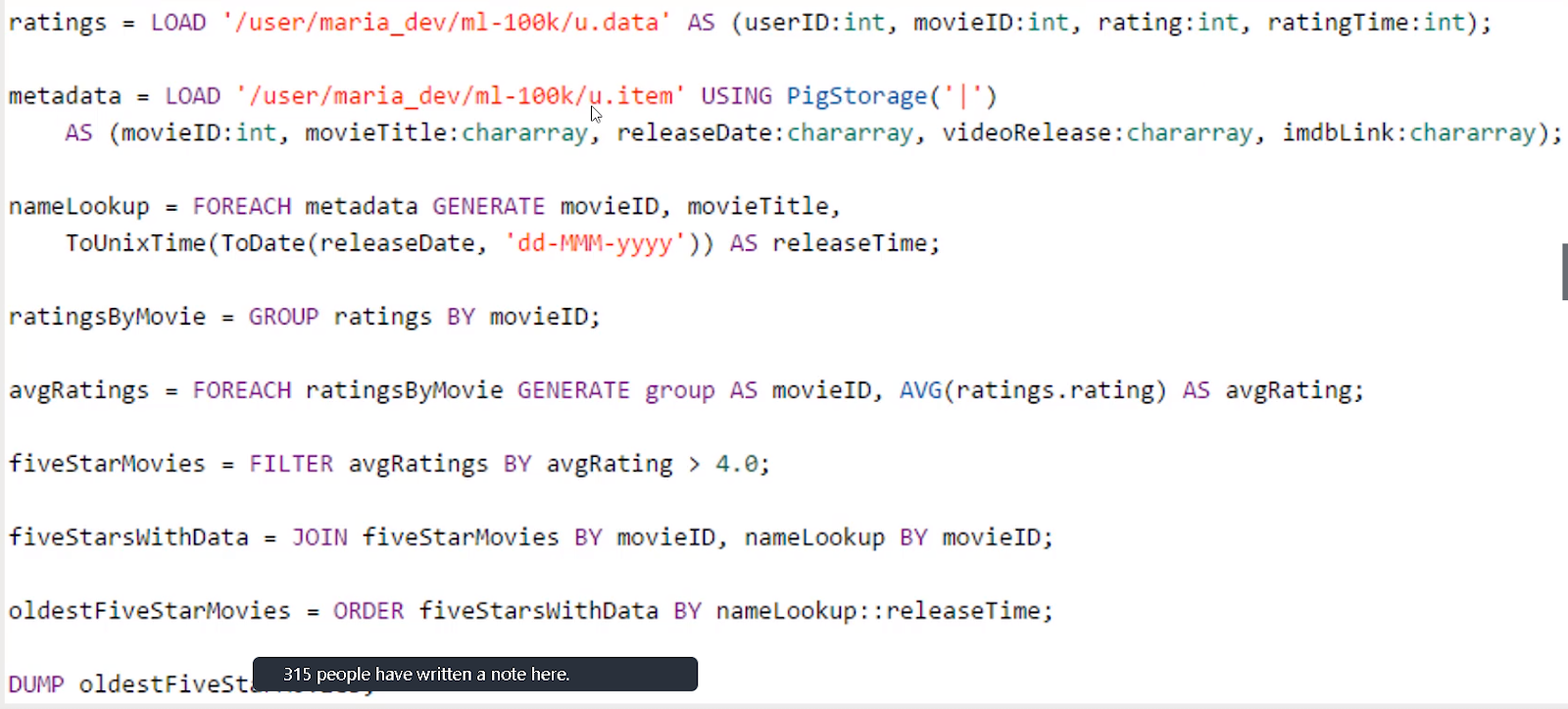
If you execute this with Tez integrated , it runs faster.
Apache Spark
A fast and general engine for large scale data processing.


Creating RDDs
RDD is a Resilient Distributed Dataset. It is a data set but specialized on which is used by the spark framework to distribute it across various nodes.

Hive
Apache Hive is a data warehouse software project built on top of Apache Hadoop for providing data query and analysis.

When to use

Why not hive?

How Hive Works?
Let’s say you create a table. So it will store the table data into HDFS and will be stored as a delimited text file. There is no structure information saved here.
Besides this it maintains a “metastore” which stores the metadata about this.
Hive uses HQL to get data.

Load data deals with BigData. Load Data local is non big data.
Managed table – hive takes ownership of the table. So if you write a drop table then it will drop data and structure.
External table- hive does not take ownership of it. So if you write a drop table then it will drop data but not its structure. This is useful in cases where some other Big Data applications want to use the structure of table
Partitioning
Hive works very well with partitioning. It will manage the partitions separately. So lets say in case of address it can very well partition with the country name. This will improvise the query execution time.
Alternative to Hive – IMPALA (Cloudera) – faster than Hive
SQOOP
Ingestion framework . Helps to import from SQL based DBs to HDFC/Hive and export to SQL as well. It also uses map reduce . When you give it a job it uses several mappers to get the task executed.
Import data from sql to HDFS

Add –hive-import to import to hive

Scaling up

Sample Architecture with NoSQL and BigData

HBase
No SQL DB made from Google’s BigTable
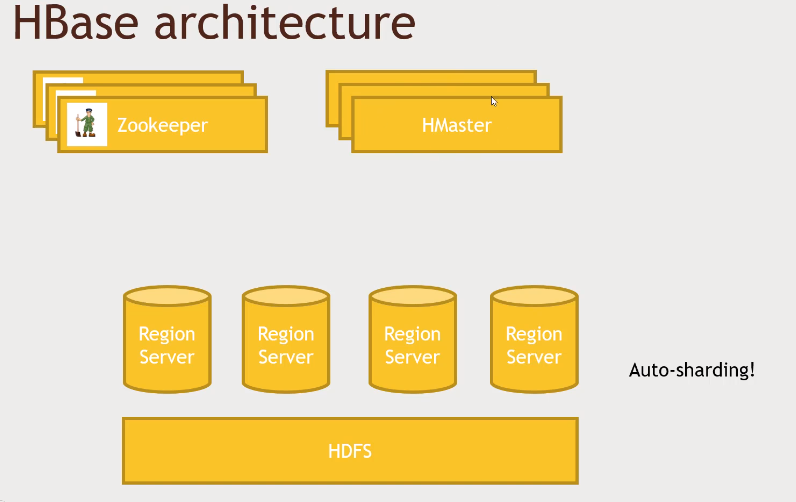
HMaster stores the partitions and information on where is what (on which region server).
ZooKeeper knows about the master and can contact another master if one goes down.

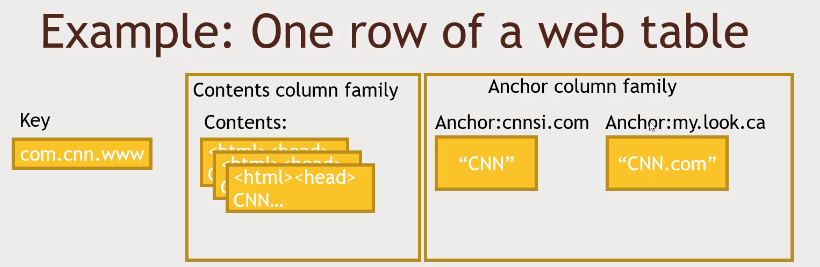
Column family can store multiple columns.
A cell can have multiple versions of them based on timestamp.
One can use Java/Python to populate into HBase. If the file already exists on HDFS then one can use PIG to load data into Hive.
Alternative to Hbase – Accumulo (better security – cell based access control)
Cassandra






MongoDB
Managing HuMONGOus data
It favours consistency over availability. It has a Document based data Model so you can store JSON/XML.
No schema is enforced.If you want it can be enforced but not a mandate.
MongoDB Terminology
1 .Databases
2. Collections – Tables
3. Documents – Rows

Sharding
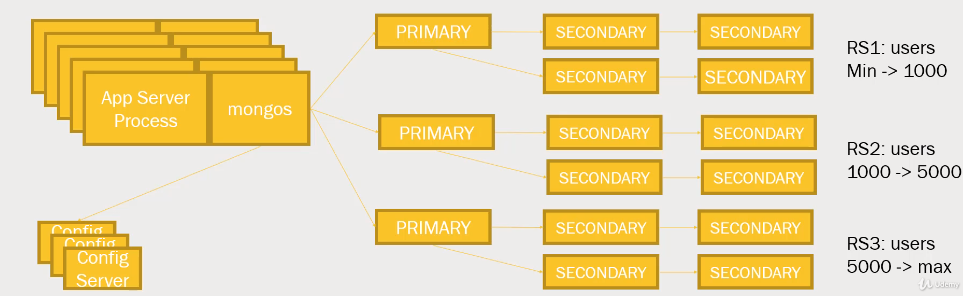

Query Engines
Apache Drill


It’s like SQL for the entire ecosystem. You can get data from MongoDB and join it with Hive and so on. There is no learning curve as it uses SQL data.
So why would one want to use Hive, MongoDB etc? Well it’s not very efficient with Big Joins.

Apache Phoenix
It’s a query engine especially for HBase. So you can use SQLs to query into HBase instead of writing a Java/Python program. It’s quick. Also connects to Pig etc



Presto


It’s made by Facebook.
Presto can query Cassandra too besides others !
Also, the UI is very good compared to Drill.

YARN – Yet Another Resource Negotiator


Apache Tez


Parallelizes steps or skips steps or removes redundant steps to improve the performance over map Reduce.


Mesos


ZooKeeper






Zookeeper favours availability over consistency
Oozie
It is used to make workflows. So lets say you need coordination between various individual jobs like SQL, Hive, MongoDB etc then we can write an xml for the steps to be performed. Each of these steps will be coordinated by oozie.







Zeppelin
It provides an interactive way to write BigData programs. It can connect to various technologies and works like a workbook.

HUE – Hadoop User Experience

It is not open source and managed by cloud era. It has an inbuilt Oozie editor to write workflows.
Kafka


Alternative to Kafka – Amazon Kinesis
Flume



Spark Streaming




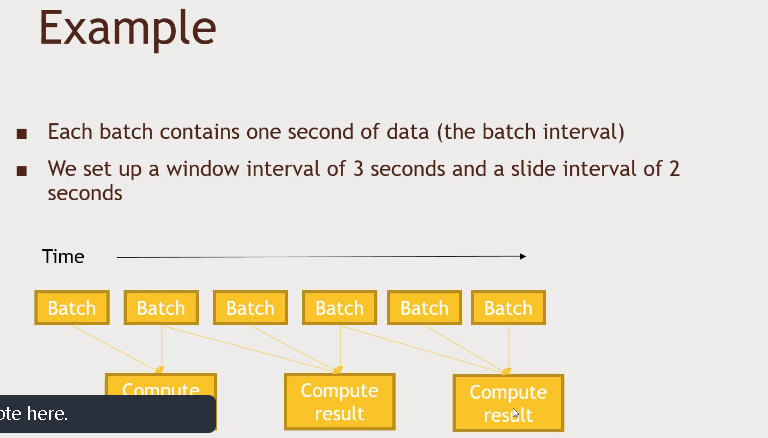
Structured Streaming
Uses DataSets instead of DataFrame


Apache Storm
Storm vs Spark Streaming




Sliding windows – have a common /overlapping part of the processing. Example 10 secs is window size so every sec 9 secs will be common to the previous one.
Tumbling windows – it has no overlap.
Flink
Can manage both event based and batch based both





Leave a Reply