Microservices are a software development technique—a variant of the service-oriented architecture (SOA) architectural style that structures an application as a collection of loosely coupled services[1] In a microservices architecture, services are fine-grained and the protocols are lightweight. The benefit of decomposing an application into different smaller services is that it improves modularity. This makes the application easier to understand, develop, test, and become more resilient to architecture erosion.
- You need make multiple spring boot applications
- Each application will have a server port running on a different port -> application.properties – server.port = x.
- The applications can share their data model objects or create copies of the model which they require.
- One application calls rest services to another and communicates.
The model needs to have an empty constructor for unmarshalling the incoming object. This is how java works as it first creates it an empty object and then populates the value.
Client side vs server side load balancing
The multiple instances of the same microservice are run on different computers for high reliability and availability.
Server side load balancing is distributing the incoming requests towards multiple instances of the service.
Client side load balancing is distributing the outgoing request from the client itself.
Client-side service discovery allows services to find and communicate with each other without hard-coding hostname and port. The only ‘fixed point’ in such an architecture consists of a service registry with which each service has to register.
Eureka is used for Client Side Discovery.
Eureka clients can make a request to a service and it can also service a request. Eureka server is used as an entity to register services offered by Eureka clients.It is used as a registry server.


Creating Eureka Server
You can download the maven project for Eureka Server. It will have @EnableEurekaServer annotation.
If using Java 11 – use need to import lib for Jaxb as it has been removed from jdk.
Every Eureka Server can also act as a client as multiple such Eureka can register among each other. They can communicate for fault tolerance. So if only 1 Eureka server, you can set these to be false.

When new services are added in Eureka Server – it does not have to be restarted.
Creating Eureka Client – Add @EnableEurekaClient
Add the dependency for Spring cloud – it will make it a Eureka Client. Both server and client are contributed by netflix. Merely adding this dependency can help it to register on Eureka Server (if using default port otherwise you can define in application properties). You can change the application name from properties too.
server.port=9080
Spring.application.name=My-Service
eureka.client.serviceUrl.defaultZone=http://localhost:7777/eureka/
Now the Services has to be Changed
If a program is calling a service – it gives a full path to it http://abc.com/service. One needs to change the website name to the service name that is registered in Eureka Server.
So if Eureka server has a service called “My-Service” then the program should be calling
http://My-Service//service. This way it will not communicate directly to the service but through Eureka Server.
@LoadBalanced annotation is added over the RestTemplate so it routes through Eureka Server. Its called Ribbon.

Fault Tolerance – What part of the system will still work if there is a fault in it.
Resilient – How many faults can occur in the system so it keeps working.
How to make an architecture Fault Tolerant ?
- Multiple Instances of application
- Increase the physical sources – vertically scale it
Not a long term solution. - Timeout – if a service is slow – we would want it to timeout.
Let’s say b is slow A is not . But then Threads for B will still occupy the web servers threads.
Now if the time interval of incoming requests < Timeout we have set then it works ok. But it is bound to fail as a long term solution. - Long term solution
Circuit breaker pattern – in case if a microservice is slow/gives errors
What kind of response to give when service fails




- How has implemented the circuit breaker pattern in java – Hystrix
Step 1,2 are straightforward.
Step 3,4 – Telling the application that this method should implement circuit breaker. Also how it should behave when it breaks. Now if one of the dependencies don’t work in this function then it will go the fallback method


Hystrix is a config based circuit pattern i.e you give a config and it works on that. It’s not contributing to it anymore. The other type of circuit breakers are adaptive based which would adapt to situations.
How it works
A proxy class is created for a class that has a method with @HystrixCommand. This proxy class’s function is called when the service is invoked. Then if the function returns error then it calls the fallback function.

In the above function, the Hystrix is invoked because an external call comes to the service and so the proxy is invoked. An external call came to springframework and then it delegated the call to the proxy class.
Now this works for one service. Lets say if we want to give a fallback function for every dependency service that we call to make the present service work i.e a granular level of fallbacks.
If we make a separate function for every dependency call and have a fallback method – the hystrix won’t be invoked. This is because – you are delegating the call to the service yourself instead of the spring managing it.
The Solution – Make a separate class for every dependency call and these should be Autowired in the consuming service so that spring manages it.
More options

TimeoutinMs – timeout
Request Volume threshold – window of requests – a group of 5 requests- it should be triggered
Error threshold % – if 50% of the requests in window fail – it should be triggered
Sleep window in ms – window measured interval
Hystrix Dashboard – include a separate dependency for it
You get all the stats and info about the service calls.

Bulkhead pattern –
The goal of the bulkhead pattern is to avoid faults in one part of a system to take the entire system down. The term comes from ships where a ship is divided in separate watertight compartments to avoid a single hull breach to flood the entire ship; it will only flood one bulkhead.
The idea is to isolate the damage to one component.

Here we have defined the thread pool name for this function. So this is specific to this function alone. Coresize – indicates max concurrent threads
Max queue size – the max threads beyond concurrent threads.
If threads go beyond this then it executes the fallback method.
General
In general, the goal of the bulkhead pattern is to avoid faults in one part of a system to take the entire system down. The term comes from ships where a ship is divided in separate watertight compartments to avoid a single hull breach to flood the entire ship; it will only flood one bulkhead.
Implementations of the bulkhead pattern can take many forms depending on what kind of faults you want to protect the system from. I will only discuss the type of faults Hystrix handles in this answer.
I think the bulkhead pattern was popularized by the book Release It! by Michael T. Nygard.
What Hystrix Solves
The bulkhead implementation in Hystrix limits the number of concurrent calls to a component. This way, the number of resources (typically threads) that is waiting for a reply from the component is limited.
Assume you have a request based, multi threaded application (for example a typical web application) that uses three different components, A, B, and C. If requests to component C starts to hang, eventually all request handling threads will hang on waiting for an answer from C. This would make the application entirely non-responsive. If requests to C are handled slowly we have a similar problem if the load is high enough.
Hystrix’ implementation of the bulkhead pattern limits the number of concurrent calls to a component and would have saved the application in this case. Assume we have 30 request handling threads and there is a limit of 10 concurrent calls to C. Then at most 10 request handling threads can hang when calling C, the other 20 threads can still handle requests and use components A and B.
Hystrix’ approaches
Hystrix’ has two different approaches to the bulkhead, thread isolation and semaphore isolation.
Thread Isolation
The standard approach is to hand over all requests to component C to a separate thread pool with a fixed number of threads and no (or a small) request queue.
Semaphore Isolation
The other approach is to have all callers acquire a permit (with 0 timeout) before requests to C. If a permit can’t be acquired from the semaphore, calls to C are not passed through.
Differences
The advantage of the thread pool approach is that requests that are passed to C can be timed out, something that is not possible when using semaphores.
Target: Microservices with Eureka Service Registry

1. Create a project for every microservice importing Eureka Discovery Client and other dependencies which it requires. @EnableEurekaClient. This gives the ability to each project to register itself with the registry.
2. Create a single project service registry importing Eureka Server dependency. @EnableEurekaServer. / If one uses Kubernetes then they get service discovery out-of-the-box.
server.port
spring.application.name
spring.h2.console.enabled
eureka.client.register-with-eureka
eureka.client.fetch-registry
eureka.client.service-url.default-zone (this will have address to Eureka Server)
eureka.client.instance.hostname
The above enables microservice interaction to others to interact using registry and taking the application-ame as the host.
Before: http://localhost:8080/payment/getDetails
After: http://payment-service{application.name}/payment/getDetails but for that we need to tell spring things have changed.
And it is supposed to use a registry in each microservice.
for that add, @LoadBalanced for each Rest call or on the RestTemplate to external service.
Target: API Gateway along with Eureka Service Registry and microservices

1. Create a project with spring cloud routing gateway as dependency. Alternative is Zuul but it has disadvantages as all calls are blocking and it uses servlet 2.5.
a. Give spring application name
b. Register it with service discovery as client
c. Give routes for every microservice
i. Spring.cloud.gateway.routes.id
ii. Spring.cloud.gateway.routes.uri
iii. Spring.cloud.gateway.routes.predicates
Target: Add Hystrix for Fallback and failure of microservices
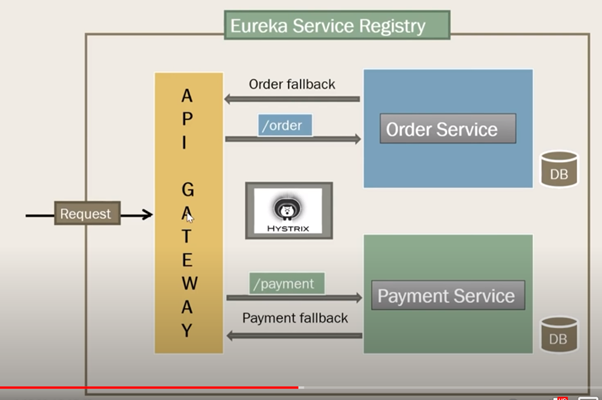
1. One can add the Hystrix dependency to API gateway itself as API gateway is the only way the clients hit our services so all common fallbacks need to be placed here.
2. Change application.yml / properties with for each of the microservices
i. spring.cloud.gateway.routes.filters.name
ii. spring.cloud.gateway.routes.filters.args.name
iii. spring.cloud.gateway.routes.filters.args.fallbackuri
3. Add the condition to invoke the fallback uri
a. Hystrix.command.fallbackcmd.excution.isolation.thread.timeoutInMilliseconds
4. @EnableHysterix
Hystrix Dashboard
1. Create a new project with a Hystrix Dashboard for monitoring all services and its failures. It will require Hystrix Dashboard dependency
2. @HystrixDashboard
Target: Add Config Server for all common configurations

All common config like service registry’s url which is configured for all microservices goes in Config server.
All the microservices interacting with each other use hardcoded urls. Only the host and port name has been changed. With common property we can attach a name to this entire URL and this can refer so essentially decoupling even more
Before : http://payment-service{application.name}/payment/getDetails
After:
1. Create a single git repo add an application yml file with common properties.
2. Create a config server with the dependency spring cloud config @EurekaConfigServer and make it EurekaClient @EurekaClient
3. Besides application name and EurekaClient we need to add git repos url using
cloud.config.server.git.url
4. Change every microservice by removing the property for EurekaClient and attach
cloud.config.uri and attach spring cloud config dependency to these


Target : ELK implementation

1. Implement logger in all microservices and generate a log file for each microservice by giving.
logging.file:path in application.yml
2. Create a new index in Kibana. Start Kibana using its batch file and create an index using REST call.
3. Go to Logstash config file and change log file name (generated from our microservice) and index which we created in Kibana.
4. Start Logstash using a batch file. The logs will be printed.
5. Create a new index pattern in Kibana to search for our logs and click on discover. You will be able to see logs
Target : Zipkin implementation – for complex microservice call tracing / Distributed tracing

1. Download Zipkin server and start the batch.
2. Import Zipkin dependencies into microservices.
3. Add spring.zipkin.url: path to Zipkin to get these microservices registered.
4. Now the logs will be appended with the information 4 additional things as mentioned in the picture. Trace id remains the same throughout one call and span id changes in every call from one microservice to another.
5. Even the Zipkin page will be reflecting the call dependencies of microservices and give their traces.
Leave a Reply