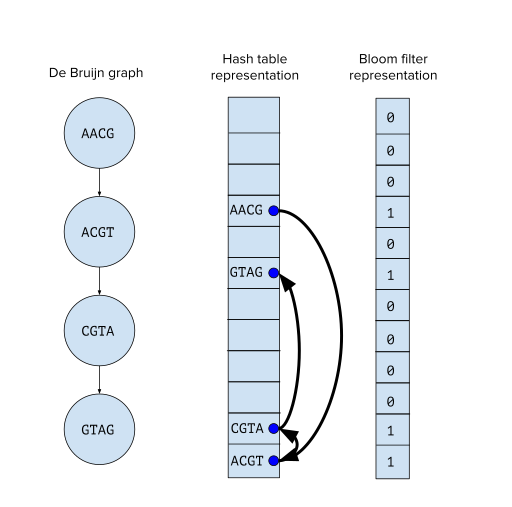
They are a probabilistic data structure. It is just a bit array.
This is used in conjunction with Disk. So every time instead of querying the disk once can check the bloom filter and know if it’s absent.
Let’s take size as 8.
_ _ _ _ _ _ _ _ _
- If you get a string “ABC” – we need to finds it Hash(“ABC”) = 3
_ _ 1 _ _ _ _ _ _
- If you get a string “ABC” – we need to finds it Hash(“DEC”) = 4
_ _ 1 1_ _ _ _ _ _
Now the structure is basically used to tell the presence or absence of an element.
IF the string is present then the hash produced by the string should be 1 else 0.
It is possible that there are collisions due to hash function giving the same value of string, so the presence is probabilistic but the absence is a surety.
To make it better, we use a much bigger size and multiple hash functions.
Use Cases
- To know if a username is taken or not
- DBs use this on most queries columns to know if an element with such a value is present or not.
- Google chrome also uses this to maintain a list of malicious websites. So it sends a long number which basically represents a bloom filter (123345435…1MB). This is checked before the user hits that website and display a warning.
Advantages
- Size is very small
- Faster to search this than a huge data structure.
Leave a Reply